CS 6901, Projects in Computer Science
Fall 2005
Advisors: Dr. Markus Hofmann, Dr. Henning Schulzrinne, Salman Abdul Baset
NoTorrent is a system that uses peer-to-peer web serving in an attempt to counter the Slashdot Effect (also known as flash crowds or web hotspots).
The Slashdot Effect [1] gets its name from the following phenomenon. Slashdot.org [2], which is a website that aggregates links to articles about technology, has a readership of roughly half a million people (as of 10/11/2004) [3]. Many of the articles are on NYTimes.com and other websites that can handle sudden, large volumes of traffic. However, some of the articles linked to are on relatively obscure and diminutive websites, which do not expect and often cannot handle a sudden burst of web requests. The sudden large volume of traffic can often bring down or at least significantly slow down these small websites. This means that the Slashdot readers cannot access the content they requested. (See figure 1.)
Another example of the Slashdot Effect occurred on September 11, 2001, when many news websites were slowed to a crawl by the large volume of web requests. It is this phenomenon that we seek to address.
|
NoTorrent's setup is as follows:
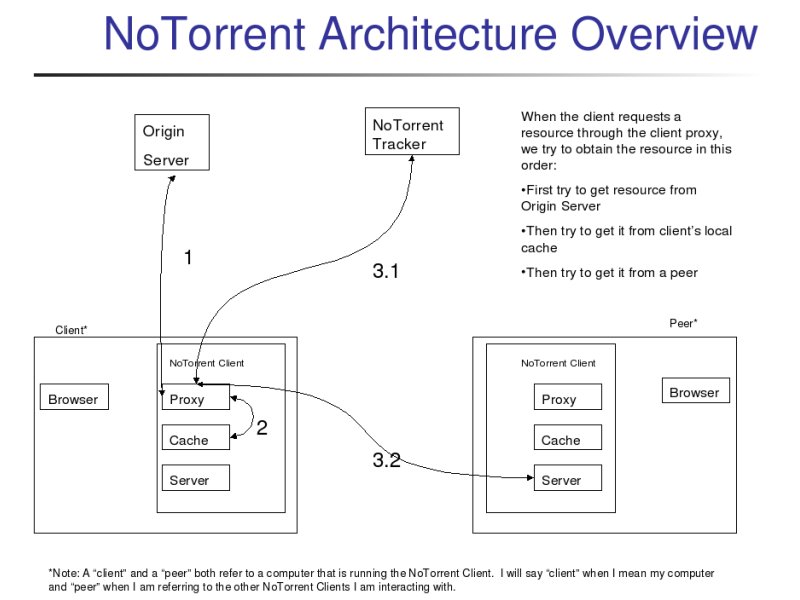 |
Users run a NoTorrent client on their local machine. A designated tracker machine runs a NoTorrent tracker. The NoTorrent client consists mainly of:
The user configures his web browser to use the NoTorrent web proxy (see the README). When a user requests a webpage through his browser, the browser ask the NoTorrent proxy to retrieve the file. It is then the client's NoTorrent proxy's responsibility to retrieve the file.
NoTorrent, as should any caching system, has a duty to "Do no harm." That is, NoTorrent is designed to be as transparent as possible and to only be used if it is necessary.
Thus, the proxy tries first to request the file from the origin server, as would be done if NoTorrent had not been installed. Only if the origin server fails to serve the resource will NoTorrent really get involved.
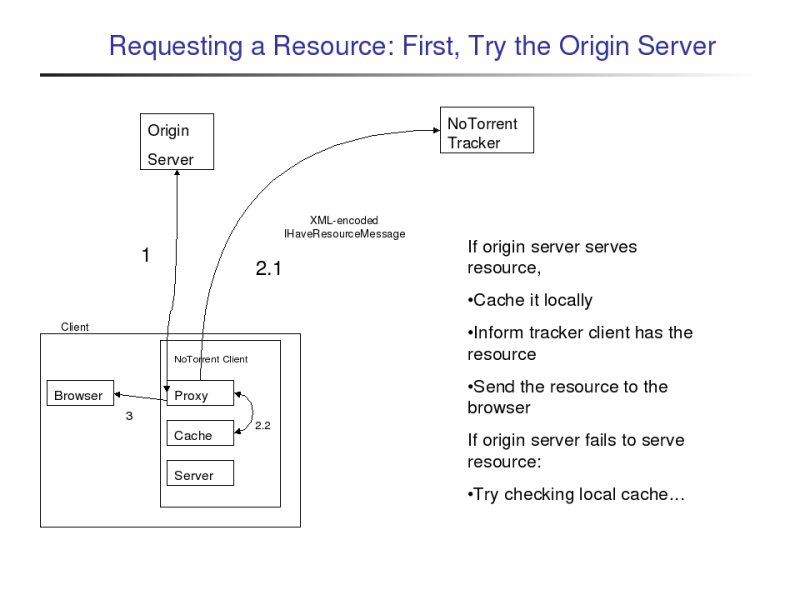 |
If the origin server fails to serve the resource, the proxy then looks in its local cache for the resource. If the client had earlier retrieved the file either from the origin server when it was still up or from a peer (discussed below), then the file will be in the client's cache, and it will be sent to the browser.
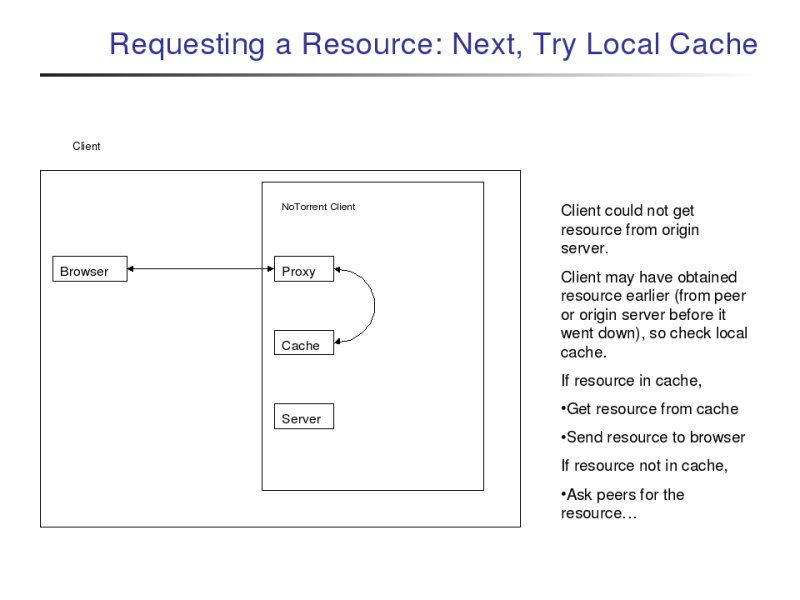 |
If both the origin server and the client's cache failed to serve the resource, then the proxy will try to retrieve the resource from a NoTorrent peer. To do this, the proxy must first contact the NoTorrent tracker. The NoTorrent tracker is a program that tracks which peers claim to have which resources and provides this information to clients upon request. (Note: A "client" and a "peer" both refer to a computer that is running the NoTorrent client. I will say "client" when I mean my computer and "peer" when I am referring to the other NoTorrent clients I am interacting with.)
Anyhow, the proxy asks the tracker which peers claim to have the requested resource, and the tracker responds with a list of peers that claim to have the requested resource. (If no peers claim to have the resource, an empty list is returned.)
The proxy then proceeds to sequentially ask the peers on the list for the resource. If a peer sends the file to the proxy, the proxy sends the file to the browser.
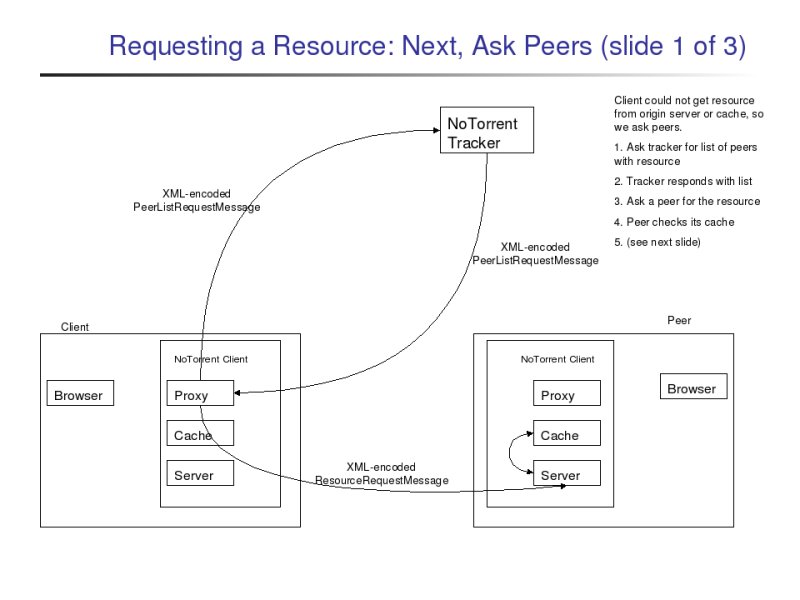 |
To keep the tracker's resource to peer list mapping current, the peers must send messages to it to keep it informed.
When a proxy retrieves a copy of a resource either from the origin server or from a peer, it sends a message to the tracker informing it that it has a copy of the resource.
When a client requests a resource from a peer and that peer fails to serve the resource, the client sends the tracker a message informing it that the peer failed to serve the content.
When a proxy retrieves a copy of a resource either from the origin server or from a peer, it also caches a copy of the resource. The client's cache is used both to handle requests by that client and also to handle requests made by peers. The peers' requests are handled by the client's server, which waits listening for connections.
Going back further in history of this project, I originally built a precursor to this project (called PeDiCache) for CS 6998.9, Content Networking, at Columbia in the spring of 2005. At the time I designed that project, I was not familiar with the architecture of BitTorrent. PeDiCache too used a tracker (then called an index server) and client proxies in a manner similar to NoTorrent. My rationale in choosing that architecture at the time was that, while any peer-to-peer system with a centralized server (and thus a single point of failure) was not a true peer-to-peer system, my experience (from several years prior) was that the original Napster (which was based on a centralized index server) operated much more smoothly than Gnutella (which is true peer to peer). Thus, I figured that a peer-to-peer web caching and server system was worth implementing as an experiment. There are other approaches to attempting to counter the Slashdot Effect (see Related Work below), but PeDiCache and NoTorrent are my attempts at a different approach.
Another benefit of this architecture is the benefit that is inherent in most peer-to-peer applications: While availability worsens as more users request content in the client-server model, in peer-to-peer applications, availability tends to increase as users request (and thus serve) content. That is, since peers serve content to other peers in a peer-to-peer application, more users on the system means there will be more servers available.
The system comprises about 4,000 lines Java code. All code was written from scratch. JDOM [4] was used to greatly simplify XML parsing in Java.
NoTorrent was originally intended to be a version of BitTorrent slightly modified so that it did not use .torrent files. As I worked with and researched BitTorrent further, I found that .torrent files are integral to almost every aspect of BitTorrent and that it could not just be "slightly modified" to be used without .torrent files. Thus, I decided it made more sense to write the application from scratch rather than start with the BitTorrent codebase and modify it. Still, NoTorrent was designed with BitTorrent in mind, and the overall structure is roughly the same.
The main purpose of BitTorrent is to enable peers to help each other download a large file. There are a few steps [5] to share a file via BitTorrent:
As I developed NoTorrent, it became clearer that NoTorrent would have less in common with BitTorrent than I originally thought. However, NoTorrent has several similar analogs to BitTorrent's setup:
In hindsight, NoTorrent is now only similar to BitTorrent in that
Other approaches have been attempted to try to handle flash crowds on the web. Most of these approaches (including BitTorrent) require the content provider to somehow prepare for a flash crowd. These approaches are useful in situations where a flash crowd might reasonably be expected but the cost of building up a more robust server architecture cannot be justified. That is, the content provider only expects rare traffic spikes, not sustained heavy traffic. One such solution is DotSlash [6], which is elegant in that it requires no effort by clients; effort is only required on the part of the content provider. However, there are many cases in the problem at hand (namely maintaining availability of content linked to by Slashdot) where a content provider would have no expectation of being flooded by a flash crowd.
An approach somewhat similar to the one discussed here is the PROOFS [7] project. It is similar in that it uses peer-to-peer to address the problem of flash crowds. It is also elegant in that it requires no effort on the part of the content provider or any other centralized server; effort is only required on the part of the clients. PROOFS seems to be a promising approach to address the problem we have set out to solve.
Most of the other approaches I have encountered required the content provider (the origin server) to prepare for a high volume of traffic. In NoTorrent, the origin server need take no action to prepare for a flash crowd. This is important, because flash crowds are typically unexpected (if they had been expected, the content provider likely would have set up a more robust server architecture).
For the problem domain I am addressing, it is the people who want the content (the Slashdot readers) who provide the capacity for others to obtain the content. Thus, incentives are more properly aligned.